# © 2022 starsein <dbtjd1928@gmail.com>
import csv
import datetime as dt
import pytz
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from typing import List, Tuple
# 입출력에 사용되는 파일 목록
DATA_CSV = 'data.csv'
TODO_LIST_CSV = 'todoList.csv'
COMPLETED_TASK_LIST_CSV = 'completedTaskList.csv'
# data.csv 의 컬럼별 항목 분류
DATE = 0
WEEKDAY = 1
UNCOMPLETED_TASK_LIST = 2
UNCOMPLETED_TASK_NUM = 3
COMPLETED_TASK_LIST = 4
COMPLETED_TASK_NUM = 5
def update_data():
with open(DATA_CSV, 'r', encoding='utf-8-sig') as rf:
total_data = rf.readlines()
if len(total_data) == 0:
return
recent_date_str = total_data[-1].split(',')[DATE]
today_obj = dt.date.fromisoformat(get_today_weekday()[0])
target_day_obj = dt.date.fromisoformat(recent_date_str) + dt.timedelta(days=1)
updating_data_list = []
while target_day_obj < today_obj:
target_day_str = target_day_obj.strftime("%Y-%m-%d")
target_weekday_str = weekday_en_to_kr(target_day_obj.isoweekday())
updating_data_list.append([target_day_str, target_weekday_str, [], 0, [], 0])
target_day_obj += dt.timedelta(days=1)
if len(updating_data_list):
unsaved_todo = get_todo()
unsaved_completed_task = get_completed_task()
updating_data_list[0][2] = unsaved_todo
updating_data_list[0][3] = len(unsaved_todo)
updating_data_list[0][4] = unsaved_completed_task
updating_data_list[0][5] = len(unsaved_completed_task)
with open(TODO_LIST_CSV, 'w', encoding='utf-8-sig', newline=''):
pass
with open(COMPLETED_TASK_LIST_CSV, 'w', encoding='utf-8-sig', newline=''):
pass
with open(DATA_CSV, 'a', encoding='utf-8-sig', newline='') as af:
writer = csv.writer(af)
writer.writerows(updating_data_list)
def add_todo():
print("[할 일 추가]")
with open(TODO_LIST_CSV, 'a', encoding='utf-8-sig', newline='') as af:
writer = csv.writer(af)
print("오늘 할 일을 입력하세요.",
"이전 메뉴로 돌아가려면 q 또는 Q를 입력하세요.", sep='\n')
while True:
todo_str = input().rstrip()
if todo_str == 'q' or todo_str == 'Q':
return 0
writer.writerow([todo_str])
print(f"{todo_str}가 할 일 목록에 정상적으로 추가되었습니다!")
def get_todo() -> List[str]:
with open(TODO_LIST_CSV, 'r', encoding='utf-8-sig') as rf:
todo_list = []
reader = csv.reader(rf)
for todo in reader:
todo_list.append(*todo)
return todo_list
def show_todo():
print("[할 일 확인]")
todo_list = get_todo()
print("+------------------------------------+")
for idx, todo in enumerate(todo_list, start=1):
print(idx, todo)
print("+------------------------------------+")
while True:
cmd = input("이전 메뉴로 돌아가려면 q 또는 Q를 입력하세요.\n").rstrip()
if cmd == 'q' or cmd == 'Q':
return 0
def add_completed_task():
print("[해낸 일 추가]")
todo_list = get_todo()
with open(COMPLETED_TASK_LIST_CSV, 'a', encoding='utf-8-sig', newline='') as af:
writer = csv.writer(af)
print("오늘 해낸 일을 입력하세요.",
"이전 메뉴로 돌아가려면 q 또는 Q를 입력하세요.", sep='\n')
while True:
print("[현재 할 일 목록]")
print("+------------------------------------+")
for idx, todo in enumerate(todo_list, start=1):
print(idx, todo)
print("+------------------------------------+")
todo_str = input().rstrip()
if todo_str == 'q' or todo_str == 'Q':
break
if todo_str not in todo_list:
print("오늘 할 일에 없는 입력입니다.")
continue
todo_list.remove(todo_str)
writer.writerow([todo_str])
with open(TODO_LIST_CSV, 'w', encoding='utf-8-sig', newline='') as wf:
writer = csv.writer(wf)
for todo in todo_list:
writer.writerow([todo])
def get_completed_task() -> List[str]:
with open(COMPLETED_TASK_LIST_CSV, 'r', encoding='utf-8-sig') as rf:
ct_list = []
reader = csv.reader(rf)
for completed_task in reader:
ct_list.append(*completed_task)
return ct_list
def show_completed_task():
print("[해낸 일 확인]")
ct_list = get_completed_task()
print("+------------------------------------+")
for idx, completed_task in enumerate(ct_list, start=1):
print(idx, completed_task)
print("+------------------------------------+")
while True:
cmd = input("이전 메뉴로 돌아가려면 q 또는 Q를 입력하세요.\n").rstrip()
if cmd == 'q' or cmd == 'Q':
return 0
def check_data(today_str: str) -> Tuple[str, List[List[str]]]:
with open(DATA_CSV, "r", encoding='utf-8-sig') as rf:
data_list = []
reader = csv.reader(rf)
for day_data in reader:
data_list.append(day_data)
date = day_data[0]
if date == today_str:
print("현재 날짜에 이미 저장된 데이터가 있습니다.")
while True:
user_cmd = input("새로운 데이터로 덮어쓰기 하시겠습니까? [y/n]").rstrip()
if user_cmd == 'y':
return "OVERWRITE", data_list
elif user_cmd == 'n':
return "DON\'T OVERWRITE", data_list
return "NOT TO OVERWRITE", data_list
def weekday_en_to_kr(weekday_int: int) -> str:
translate_table = {1: "월",
2: "화",
3: "수",
4: "목",
5: "금",
6: "토",
7: "일"}
return translate_table.get(weekday_int)
def get_today_weekday() -> Tuple[str, str]:
KST = pytz.timezone('Asia/Seoul')
info = dt.datetime.now(KST)
today_str = info.strftime("%Y-%m-%d")
weekday_str = weekday_en_to_kr(info.isoweekday())
return today_str, weekday_str
def store_data():
today_str, weekday_str = get_today_weekday()
todo_list = get_todo()
ct_list = get_completed_task()
res, data_list = check_data(today_str)
if res == "OVERWRITE":
data_list.pop()
elif res == "DON\'T OVERWRITE":
return 0
else:
pass
data_list.append([today_str, weekday_str, todo_list, len(todo_list), ct_list, len(ct_list)])
with open(DATA_CSV, 'w', encoding='utf-8-sig', newline='') as wf:
writer = csv.writer(wf)
writer.writerows(data_list)
with open(TODO_LIST_CSV, 'w', encoding='utf-8-sig', newline=''):
pass
with open(COMPLETED_TASK_LIST_CSV, 'w', encoding='utf-8-sig', newline=''):
pass
print("오늘의 데이터 집계 및 초기화가 완료되었습니다!")
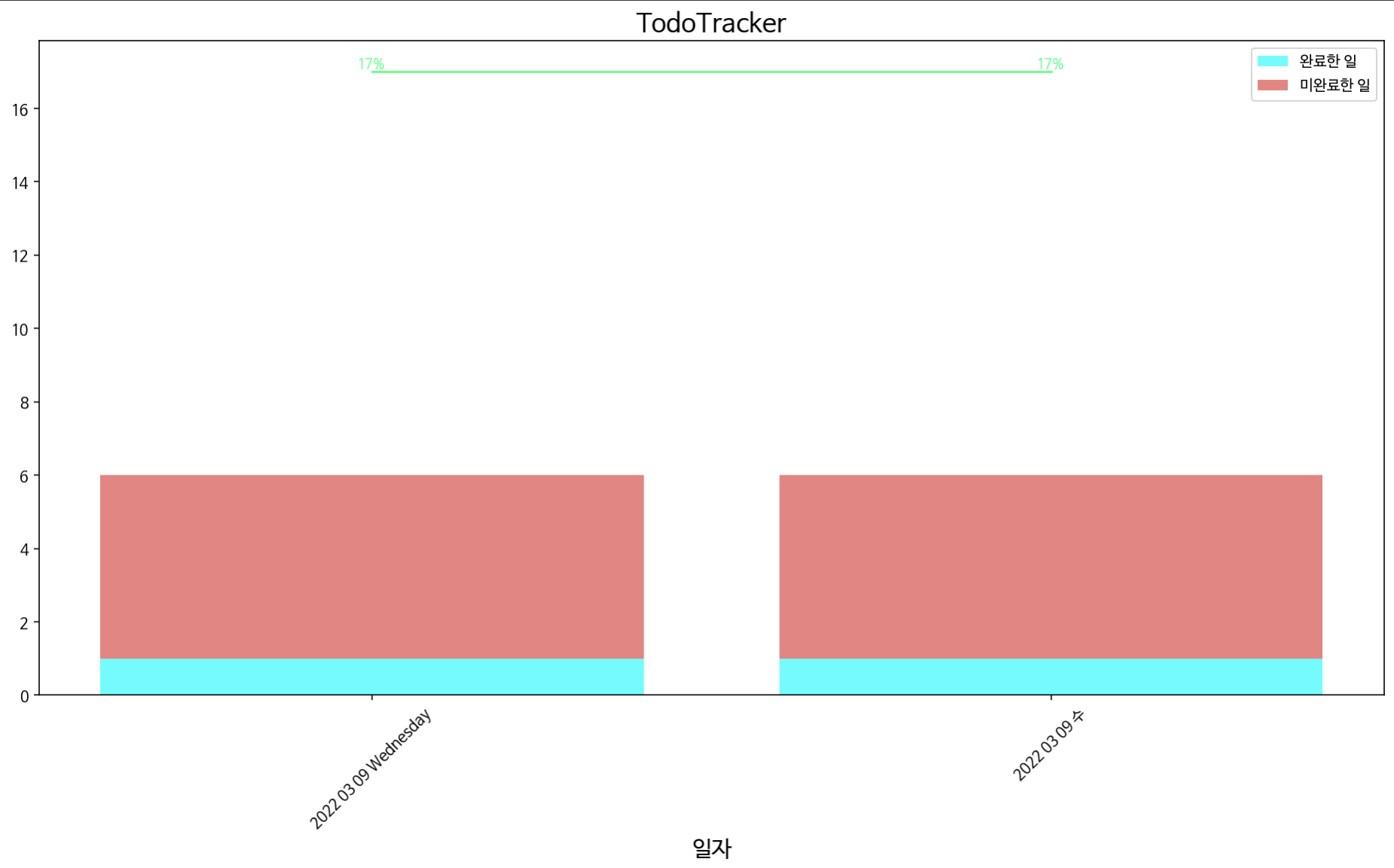
def visualize_data():
date_arr = np.array([])
num_t_arr = np.array([])
num_ct_arr = np.array([])
cr_arr = np.array([])
with open(DATA_CSV, 'r') as rf:
reader = csv.reader(rf)
for data in reader:
stored_date, stored_weekday, ut, num_ut, ct, num_ct = data
num_ut = int(num_ut)
num_ct = int(num_ct)
date_arr = np.append(date_arr, stored_date)
num_t_arr = np.append(num_t_arr, num_ut + num_ct)
num_ct_arr = np.append(num_ct_arr, num_ct)
cr = round(num_ct / (num_ct + num_ut) * 100) if num_ct | num_ut != 0 else 0
cr_arr = np.append(cr_arr, cr)
print("[현재까지 집계된 데이터 시각화]")
print(f"총 {len(date_arr)}개 날짜의 데이터가 저장되어 있습니다.")
user_cmd = int(input("최근에 저장된 데이터를 몇 개까지 표시할까요?\n"))
date_arr = date_arr[-user_cmd:]
num_ct_arr = num_ct_arr[-user_cmd:]
num_t_arr = num_t_arr[-user_cmd:]
cr_arr = cr_arr[-user_cmd:]
data_dict = {'date': date_arr,
'num_t': num_t_arr,
'num_ct': num_ct_arr,
'cr': cr_arr}
data_df = pd.DataFrame(data=data_dict)
plt.figure(figsize=(16, 8))
plt.title("TodoTracker", fontsize=25)
sns.set_style('darkgrid')
sns.set_context('notebook')
sns.barplot(x='date', y='num_t', data=data_df, palette='OrRd')
sns.barplot(x='date', y='num_ct', data=data_df, palette='GnBu')
sns.lineplot(x='date', y='cr', data=data_df, color='limegreen', marker='o', linestyle='-.')
for i, v in enumerate(date_arr):
plt.text(v, cr_arr[i], f"{int(cr_arr[i])}%", fontsize=13, fontfamily='monospace', horizontalalignment='center',
verticalalignment='bottom', color='limegreen')
plt.xlabel("Date", fontsize=15)
plt.ylabel(" ")
plt.xticks(rotation=45)
plt.show()
def show_date_streak():
presence_date_set = set()
with open(DATA_CSV, 'r') as rf:
reader = csv.reader(rf)
curr_cnt = 0
max_cnt = 0
for day_data in reader:
_date = day_data[0]
presence_date_set.add(_date)
if day_data[COMPLETED_TASK_NUM]:
curr_cnt += 1
max_cnt = max(max_cnt, curr_cnt)
else:
curr_cnt = 0
NUM_WEEK = 53
NUM_WEEKDAY = 7
matrix = [[" " for row in range(NUM_WEEK + 2)] for col in range(NUM_WEEKDAY + 1)]
matrix[0][0], matrix[1][0], matrix[2][0], matrix[3][0], matrix[4][0], matrix[5][0], matrix[6][0]\
= "S ", "M ", "T ", "W ", "T ", "F ", "S "
today_obj = dt.date.fromisoformat(get_today_weekday()[0])
a_year_ago_obj = today_obj - dt.timedelta(days=364)
a_year_ago_weekday = a_year_ago_obj.isoweekday() % 7
col = a_year_ago_weekday
row = 2
curr_day_obj = a_year_ago_obj
while curr_day_obj <= today_obj:
curr_day_str = curr_day_obj.strftime("%Y-%m-%d")
BLACK_FLAG = "\u2691 "
WHITE_FLAG = "\u2690 "
if curr_day_str in presence_date_set:
matrix[col][row] = BLACK_FLAG
else:
matrix[col][row] = WHITE_FLAG
if curr_day_obj.day == 1:
if curr_day_obj.month == 1:
matrix[7][row] = f"{curr_day_obj.year}"
try:
matrix[7][row+1] = ""
except IndexError:
pass
else:
matrix[7][row] = f"{curr_day_obj.month}월"
try:
matrix[7][row+1] = " "
except IndexError:
pass
curr_day_obj += dt.timedelta(days=1)
col += 1
if col == 7:
col = 0
row += 1
print(f"최대 {max_cnt}일 연속 하루 관리, 현재 {curr_cnt}일", end=' ')
if max_cnt == curr_cnt:
print("!!!\n")
else:
print()
for c in range(NUM_WEEKDAY + 1):
for r in range(NUM_WEEK + 2):
print(matrix[c][r], end='')
print()
def main():
update_data()
func_str_dict = {1: "할 일 추가",
2: "할 일 확인",
3: "해낸 일 추가",
4: "해낸 일 확인",
5: "오늘의 데이터 집계 및 초기화",
6: "현재까지 집계된 데이터 시각화",
7: "플래그 스트릭 조회"}
func_exec_dict = {1: "add_todo()",
2: "show_todo()",
3: "add_completed_task()",
4: "show_completed_task()",
5: "store_data()",
6: "visualize_data()",
7: "show_date_streak()"}
while True:
current_date, cw = get_today_weekday()
cy, cm, cd = current_date.split('-')
print("+--------------------+",
"| TodoTracker v1.1.2 |",
"+--------------------+",
f"# 오늘은 {cy}년 {cm}월 {cd}일 {cw}요일",
"사용하고자 하는 기능의 번호를 입력하세요!",
"프로그램을 종료하려면 기능의 번호 이외의 숫자나 문자를 입력하세요.", sep='\n')
print("+--+---------------------------+")
for func_key, func_str in func_str_dict.items():
print(f"|{func_key:>2d}|{func_str}")
print("+--+---------------------------+")
try:
user_cmd = int(input())
except ValueError:
break
try:
exec(func_exec_dict[user_cmd])
except KeyError:
break
print("프로그램을 종료합니다.",
"이용해주셔서 감사합니다!", sep='\n')
return 0
if __name__ == '__main__':
main()